Day 2: Six Degrees of Wikipedia


For the first experiment, I'm going to work with my friend and colleague Mo Mahler to build WikiWiki, a Wordle-like puzzle game where players try to get from one Wikipedia article to another only by clicking links within the articles.
There is an existing implementation of this game (it also exists informally), but we aren't fans of the game structure for that one (particularly the time limitations). Wordle has become popular lately, we think, for a few reasons: it's a easily-understandable concept, the UI is clean and straightforward, the scoring is elegant, and the shareable is created using plain text & emojis (which are copied to the user's clipboard). By using these guidelines, we hope to make an engaging and fun game to rival it.
To start, I'm going to explore the Six Degrees of Wikipedia project (and its codebase), which has done the difficult part of downloading the entirety of Wikipedia and parsing it for page links.
Process
sdow
In order to score WikiWiki, we need to be able to figure out the ideal path(s) between the start and final articles. This means that we'll need to be able to run analysis and searches across the entirety of Wikipedia.
I thought that was going to be difficult, but amazingly, someone has already solved the problem: Jacob Wenger (jwngr) with sdow. That repo has a great README on how to acquire the Wikipedia dataset the hard way, but it also has directions on downloading pre-made databases that will fit our use case.
Cloning the database
First, I need to create a GCP (Google Cloud) project for WikiWiki (since the data is stored in another GCP bucket) then install the gcloud and gsutil command line tools, and copy the dataset to my project. The most recent database was compiled in January 2021, but that's fine for prototyping. Downloading it to my machine took a few minutes (it was about 4GB).
I was a little worried there would be some cost associated with the download (jwngr mentions it, and I needed to connect a credit card to the GCP project), but it looks like the download was free.
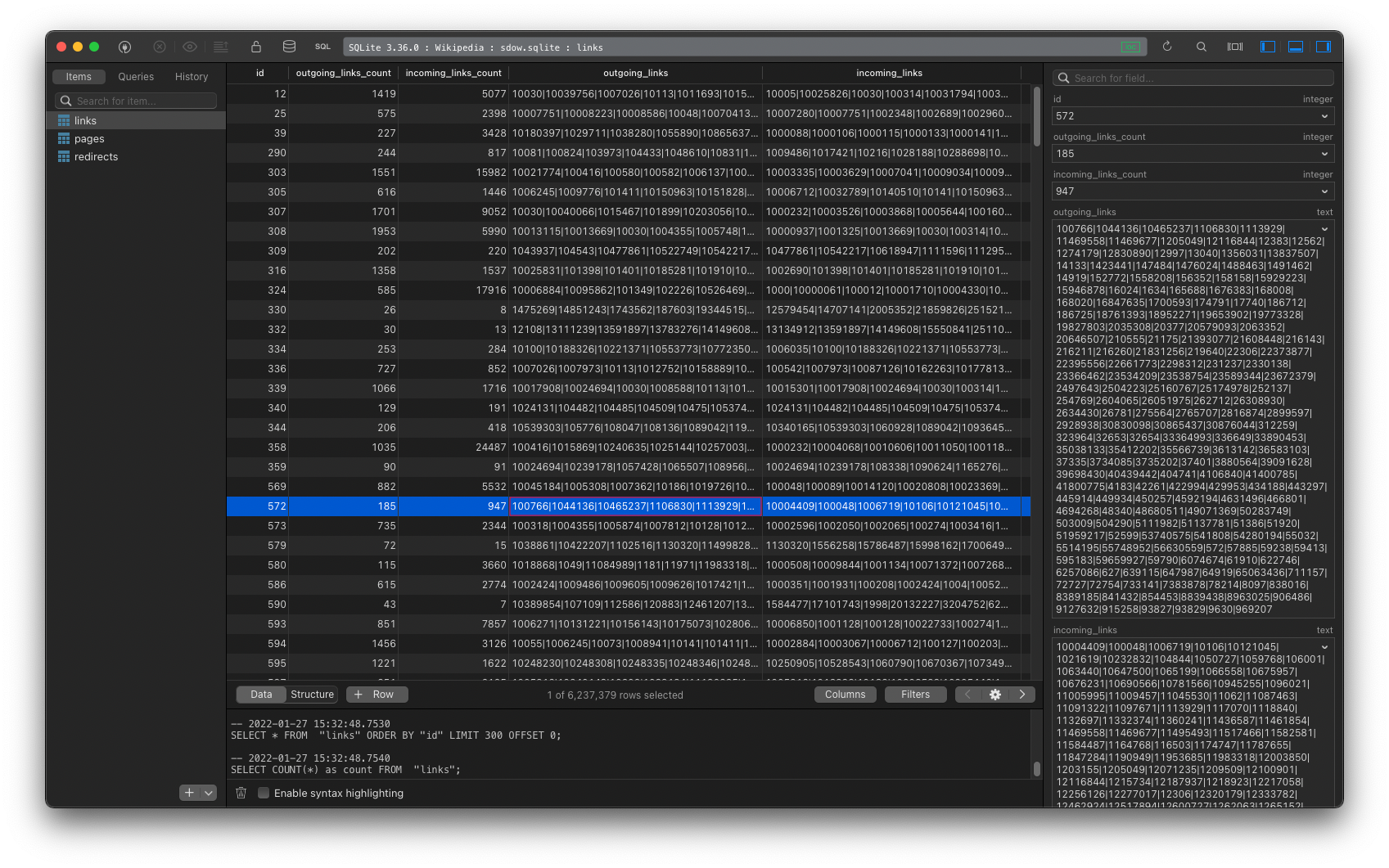
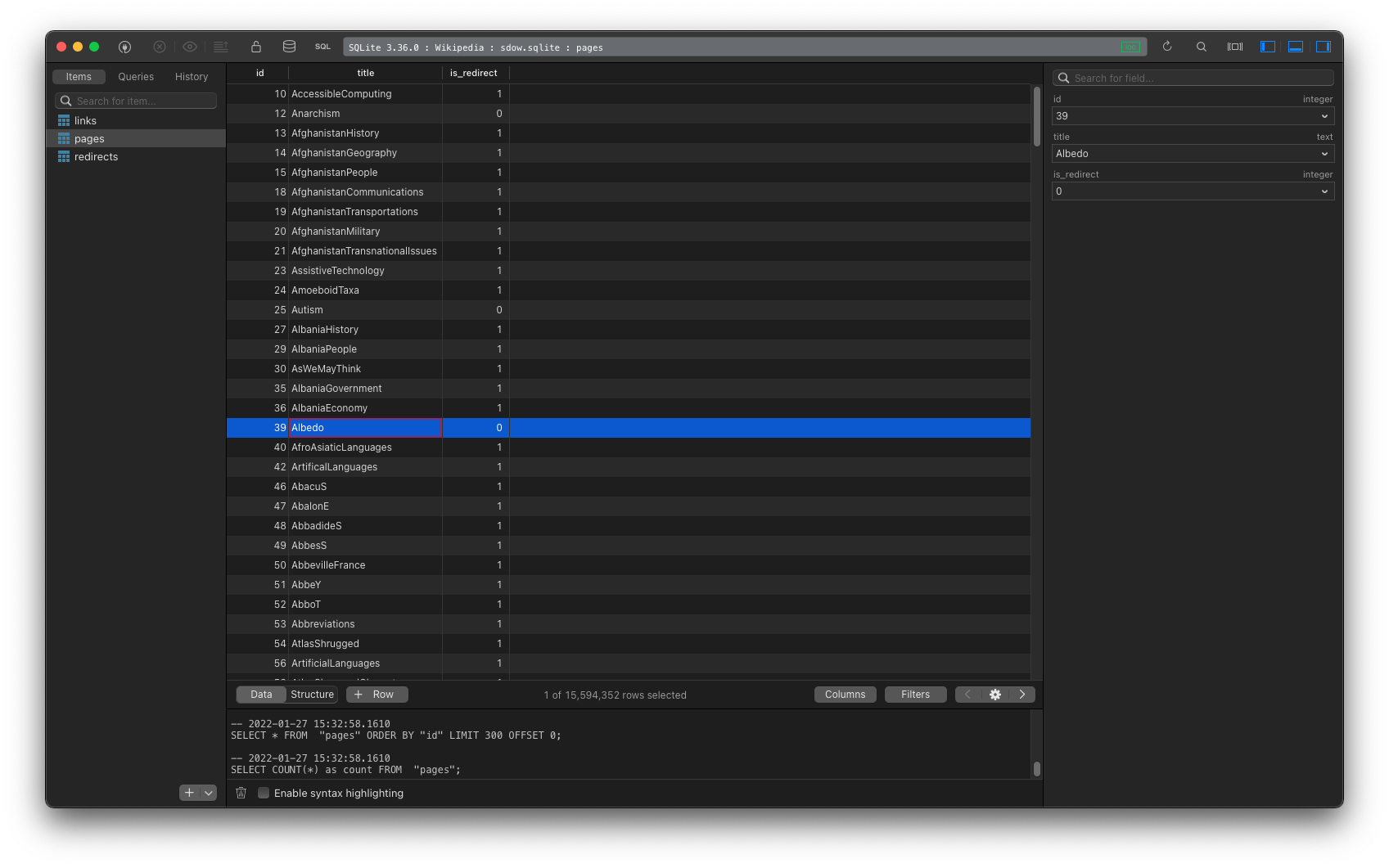
After unzipping the sqlite file, I opened it with TablePlus. There were three tables: links, pages, and redirects.
Analyzing the database
The pages table had about 15.6 million records, and the links table had about 6.2 million rows (i.e., 6.2 million pages either have links to, or are linked from, other pages).
Articles with the highest number of incoming links:
- International Standard Book Number (1,222,714 links)
- Geographic coordinate system (1,136,974 links)
- WorldCat (730,648 links)
Articles with the highest number of outgoing links:
- Index of Singapore-related articles (11,524 links)
- List of birds by common name (10,942 links)
- List of women writers (8,313 links)
// this one seems to have split into two separate pages since the database was generated
The high-outgoing link pages are a bit disappointing, as index/list pages aren't ideal for competitive Wikipedia speedruns/surfing.